basilisk for creating a gazette.
Named Entity Extraction is an important part of information extraction. One of the methods used for NER, requires a gazette of entities.
Basilisk (Bootstrapping Approach to Semantic Lexicon Induction using Semantic Knowledge) is a weakly supervised bootstrapping algorithm that automatically generates semantic lexicon (Thelen and Riloff, 2002).
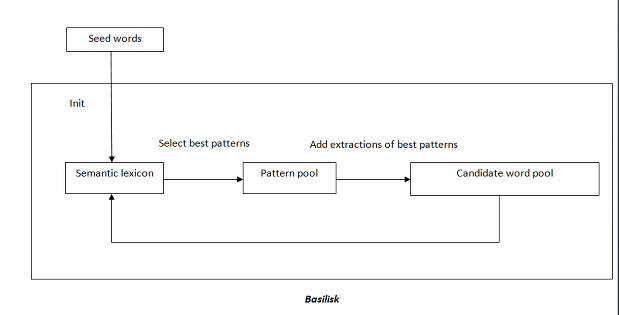
The input is a set of seed words and a corpus. Seed words are obtained by sorting the corpus on frequency and manually selecting words that could best define the gazette. Selection of seed words is important and a poor choice may be detrimental to the process, since Basilisk relies on extraction patterns. Initially, the semantic lexicon consists only of the seed words.
We start with a set of ‘m’ best extraction patterns derived from the semantic lexicon. The patterns are applied to the corpus and candidate entities are collected in the candidate word pool. The best ‘n’ candidate words are added to the semantic lexicon.
Extraction patterns are scored using RlogF (Riloff, 1996).
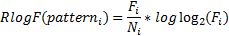
Where,
Fi is the number of extracted members Ni is the total number of entities extracted by pattern_i
The top ‘m’ patterns are added to the pattern pool. After some iterations, no new patterns will be considered, and hence a new pattern must be added in every iteration. This ensures a contribution by at least one pattern to the candidate pool on every iteration.
The candidate words are scored using,
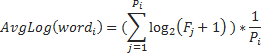
Where, Pi is the number of patterns that extract word_i. Fj is the number of entities extracted by pattern j.
After every iteration, ‘n’ best candidates are added to the lexicon. The pattern pool and the candidate pool are emptied, and the process starts over again.
I wrote a simple Perl tool to perform basilisk on a document. Extending it for a corpus is straightforward. To create a gazette of names of corporations, my seed was @entityS=(“Nokia “,”Apple “,”Microsoft “,”Google “);
Features (extraction patterns) are ‘Context rules’ which are applied to potential sentences, to extract a potential entity (Sachin Pawar, Rajiv Srivastava, Girish Keshav Palshikar, 2010).
For example, a feature context_previous_next , when applied to a sentence , ‘I work for Nokia since 1998’, extracts context_for_since. The potential entity (Nokia in this case), is added to the candidate word pool. The extracted pattern (context_for_since) is added to the pattern pool. Whether these are selected or not, depends on their score.
I used a simple feature list, @featureList= (“CONTEXT_PREV_NEXT”,”FW_WORD”,”LW_WORD”);
input S = {S1, S2, …, SJ} // set of J seed words
input F = {F1, F2, …, FK} // set of K features
input m // iterations
input e // entities to be added on every iteration
input c // Top c features
output S // set of entities (the lexicon)
L1 = feature_counts(false); //L1 is a hash
i = 0;
while i < m do
L2 = feature_counts(true);
foreach featureInstance in L2 do
c1 = L1[featureInstance];
c2 = L2[featureInstance];
s = score(c1, c2);
Add (featureInstance, s) to L;
L = select top c features
E = sorted entities
P = all phrases which are potential named entity instances;
for each p in P do
count = 0;
if p belongs S then continue; //add only unique instances
score = 0;
for each f in F do
featureInstance = apply f on p ;
if featureInstance belongs L then
score += L[featureInstance]; count++;
if count > 0 then Add (p, score/count) to E;
Select top e entities from E and add them to S; i++;
function feature_counts( flag)
L = feature->count
P = all phrases which are potential named entity instances;
for each p in P do
for each f in F do
featureInstance = apply f on p;
if flag == FALSE OR p belongs to S then
Add featureInstance to L and increment the count;
return(L);score (c1, c2) in Perl looks like :
sub score{
return ($c1==0)? 0 : $_[1]/$_[0] * log($_[1]) ;
}Since I am looking for corporations, potential phrases essentially include a series of words that start with a capital letter (can safely ignore phrases that do not fulfill this requirement). I used a regular expression to find such phrases:
sub returnPhrase{
if ( $_[0] =~ m/([A-Z][a-z]+(?=\s[A-Z])(?:\s[A-Z][a-z]+)+)/) {
return $&;
}
return '-1' ;
}And the procedure that applies the context_previous_next pattern on a potential phrase:
sub applyContextRule {
if( $_[0] =~ m/([A-Z][a-z]+(?=\s[A-Z])(?:\s[A-Z][a-z]+)+)/ ) {
@prev = split(" ",$`);
$prev = pop @prev;
@next = split(" ",$');
$next = shift @next;
my $actualPhrase = $&;
$featureIns = $featureList[0];
$featureIns = ~s/PREV/$prev/;
$featureIns = ~s/NEXT/$next/;
return ($actualPhrase,$featureIns);
}
return ('-1','-1');
}Basilisk works very well, and the gazette is fairly comprehensive within a few iterations.
The next step is NER. I plan on revisiting this and post the complete implementation in perl (with some benchmarks) soon!