A complete list of publications is available on Google Scholar. Below is a selected list.
2026
 Pareto-Guided Exploration for Multi-Objective Multiagent LearningGaurav Dixit and Kagan TumerIn International Conference on Autonomous Agents and MultiAgent Systems, 2026
Pareto-Guided Exploration for Multi-Objective Multiagent LearningGaurav Dixit and Kagan TumerIn International Conference on Autonomous Agents and MultiAgent Systems, 2026Cooperative multi-objective multiagent settings require discovering teams that realize diverse trade-offs across conflicting objectives. In multi-objective reinforcement learning, policies are typically optimized via scalarization of expected returns, while Pareto-based methods approximate sets of non-dominated solutions in objective space. In cooperative settings, however, these perspectives are typically treated in isolation. We introduce Multiagent Pareto-Led Exploration (MAPLE), a framework that couples preference-aligned actor-critic learning with Pareto dominance-based selection over expected team returns. MAPLE trains policies under multiple preference vectors while preserving and reusing agents based on their contribution to non-dominated teams through a shared archive. Empirical results in cooperative continuous-control benchmarks demonstrate improved Pareto front coverage and greater policy composability across trade-offs. These findings suggest that coupling scalarized learning with Pareto-level selection provides a principled mechanism for multi-objective multiagent learning.
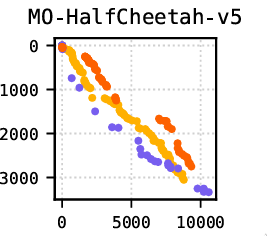 Post Hoc Extraction of Pareto Fronts for Continuous ControlRaghav* Thakar, Gaurav Dixit, and Kagan TumerarXiv preprint arXiv:2603.02628, 2026
Post Hoc Extraction of Pareto Fronts for Continuous ControlRaghav* Thakar, Gaurav Dixit, and Kagan TumerarXiv preprint arXiv:2603.02628, 2026Agents in the real world must often balance multiple objectives, such as speed, stability, and energy efficiency in continuous control. To account for changing conditions and preferences, an agent must ideally learn a Pareto frontier of policies representing multiple optimal trade-offs. Recent advances in multi-policy multi-objective reinforcement learning (MORL) enable learning a Pareto front directly, but require full multi-objective consideration from the start of training. In practice, multi-objective preferences often arise after a policy has already been trained on a single specialised objective. Existing MORL methods cannot leverage these pre-trained ‘specialists’ to learn Pareto fronts and avoid incurring the sample costs of retraining. We introduce Mixed Advantage Pareto Extraction (MAPEX), an offline MORL method that constructs a frontier of policies by reusing pre-trained specialist policies, critics, and replay buffers. MAPEX combines evaluations from specialist critics into a mixed advantage signal, and weights a behaviour cloning loss with it to train new policies that balance multiple objectives. MAPEX’s post hoc Pareto front extraction preserves the simplicity of single-objective off-policy RL, and avoids retrofitting these algorithms into complex MORL frameworks. We formally describe the MAPEX procedure and evaluate MAPEX on five multi-objective MuJoCo environments. Given the same starting policies, MAPEX produces comparable fronts at 0.001% the sample cost of established baselines.
2025
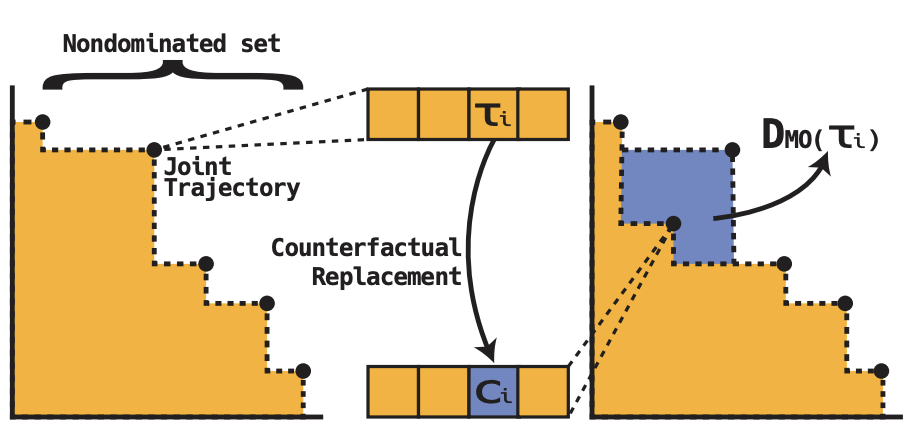 Multiagent Credit Assignment for Multi-Objective CoordinationRaghav* Thakar, Gaurav Dixit, Siddarth* Iyer, and 1 more authorIn Proceedings of the Genetic and Evolutionary Computation Conference, 2025
Multiagent Credit Assignment for Multi-Objective CoordinationRaghav* Thakar, Gaurav Dixit, Siddarth* Iyer, and 1 more authorIn Proceedings of the Genetic and Evolutionary Computation Conference, 2025Many real-world coordination tasks—such as environmental monitoring, traffic management, and underwater exploration—are best modelled as multiagent problems with multiple, often conflicting objectives. Achieving effective coordination in these settings requires addressing two main challenges: 1) balancing multiple objectives and 2) resolving the credit assignment problem to isolate each agent’s contribution from team-level feedback. Existing multiagent credit assignment methods collapse multi-objective reward vectors into a single scalar—potentially overlooking nuanced trade-offs. In this paper, we introduce the Multi-Objective Difference Evaluation (DMO) operator to assign agent-level credit without a priori scalarisation. DMO measures the change in hypervolume when an agent’s policy is replaced by a counterfactual default, capturing how much that policy contributes to each objective and to the Pareto front. We embed DMO into the popular NSGA-II algorithm to evolve a population of joint policies with distinct trade-offs. Empirical results on the Multi-Objective Beach Problem and the Multi-Objective Rover Exploration domain show that our approach matches or surpasses existing baselines, delivering up to a 33% performance improvement.
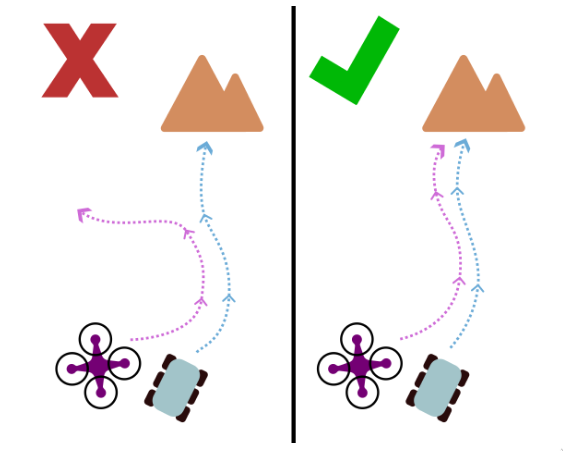 Dynamic Influence For Coevolutionary AgentsEverardo Gonzalez, Gaurav Dixit, and Kagan TumerIn Proceedings of the Genetic and Evolutionary Computation Conference, 2025
Dynamic Influence For Coevolutionary AgentsEverardo Gonzalez, Gaurav Dixit, and Kagan TumerIn Proceedings of the Genetic and Evolutionary Computation Conference, 2025Best Paper Award Finalist in the Evolutionary Machine Learning track
Multiagent settings are naturally characterized by coevolutionary dynamics, where agents must adapt and learn in the context of their teammates. A key challenge in such domains is determining how to credit an individual agent for their contribution to team performance. Fitness shaping approaches partially address this by identifying and isolating an agent’s direct contribution to the team’s success. However, when an agent’s contribution is indirect—such as influencing other teammates to succeed—existing methods fail to account for its influence on the team. This paper introduces Dynamic Influence, a fitness shaping method for heterogeneous teams that isolates both direct and indirect contributions by evaluating how agents influence others over time. By considering inter-agent influence at a high temporal resolution, Dynamic Influence-Based Fitness Shaping allows agents to distill and extract direct credit from indirect interactions. Results in an autonomous aerial and terrestrial vehicle coordination problem demonstrate the efficacy of Dynamic Influence-Based Fitness Shaping, achieving superior cooperative behaviors compared to several static fitness shaping baselines.
 Multiagent Quality-Diversity for Effective AdaptationSiddarth* Iyer, Ayhan Alp Aydeniz, Gaurav Dixit, and 1 more authorIn ECAI, 2025
Multiagent Quality-Diversity for Effective AdaptationSiddarth* Iyer, Ayhan Alp Aydeniz, Gaurav Dixit, and 1 more authorIn ECAI, 2025Robust adaptation in multiagent settings requires learning not just a single optimal behavior, but a repertoire of high-performing and diverse team behaviors that can succeed under environmental contingencies. Traditional multiagent reinforcement learning methods typically converge to a single specialized team behavior, limiting their adaptability. Recent approaches like Mix-ME promote behavioral diversity but rely solely on evolutionary operators, often resulting in sample-inefficiency and uncoordinated team composition. This work introduces Multiagent Sample-Efficient Quality-Diversity (MASQD), a learning framework that produces an archive of diverse, high-performing multiagent teams. MASQD builds on the Cross-Entropy Method Reinforcement Learning algorithm and extends it to the multiagent setting by representing teams as parameter-shared neural networks, directing exploration from previously discovered behaviors, and guiding refinement through a descriptor-conditioned critic. Through this coupling of anchored exploration and targeted exploitation, MASQD produces functional diversity: teams that are not only behaviorally distinct but also robust and effective under varied conditions. Experiments across four Multiagent MuJoCo tasks show that MASQD outperforms state-of-the-art baselines in both team fitness and functional diversity.
2024
 Influence-Focused Asymmetric Island ModelAndrew Festa, Gaurav Dixit, and Kagan TumerIn Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, 2024
Influence-Focused Asymmetric Island ModelAndrew Festa, Gaurav Dixit, and Kagan TumerIn Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, 2024Learning good joint-behaviors is challenging in multiagent settings due to the inherent non-stationarity: agents adapt their policies and act simultaneously. This is aggravated when the agents are asymmetric (agents have distinct capabilities and objectives) and must learn complementary behaviors required to work as a team. The Asymmetric Island Model partially addresses this by independently optimizing class-specific and team-wide behaviors. However, optimizing class-specific behaviors in isolation can produce egocentric behaviors that yield sub-optimal inter-class behaviors. This work introduces the Influence-Focused Asymmetric Island model (IF-AIM), a hierarchical framework that explicitly reinforces inter-class behaviors by optimizing class-specific behaviors conditioned on the expectation of behaviors of the complementary agent classes. An experiment in the harvest environment highlights the effectiveness of our method in optimizing adaptable inter-class behaviors.
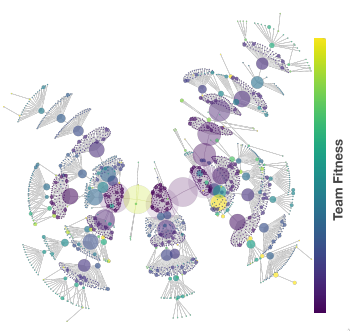 Informed Diversity Search for Learning in Asymmetric Multiagent SystemsGaurav Dixit and Kagan TumerIn Proceedings of the Genetic and Evolutionary Computation Conference, 2024
Informed Diversity Search for Learning in Asymmetric Multiagent SystemsGaurav Dixit and Kagan TumerIn Proceedings of the Genetic and Evolutionary Computation Conference, 2024Best Paper Award Finalist in the Evolutionary Machine Learning track
To coordinate in multiagent settings, asymmetric agents (agents with distinct objectives and capabilities) must learn diverse behaviors that allow them to maximize their individual and team objectives. Hierarchical learning techniques partially address this by leveraging a combination of Quality-Diversity to learn diverse agent-specific behaviors and evolutionary optimization to maximize team objectives. However, isolating diversity search from team optimization is prone to producing egocentric behaviors that have misaligned objectives. This work introduces Diversity Aligned Island Model (DA-IM), a coevolutionary framework that fluidly adapts diversity search to focus on behaviors that yield high fitness teams. An evolutionary algorithm evolves a population of teams to optimize the team objective. Concurrently, a combination of gradient-based optimizers utilize experiences collected by the teams to reinforce agent-specific behaviors and selectively mutate them based on their fitness on the team objective. Periodically, the mutated policies are added to the evolutionary population to inject diversity and to ensure alignment between the two processes. Empirical evaluations on two asymmetric coordination problems with varying degrees of alignment highlight DA-IM’s ability to produce diverse behaviors that outperform existing population-based diversity search methods.
 Reinforcing Inter-Class Dependencies in the Asymmetric Island ModelAndrew Festa, Gaurav Dixit, and Kagan TumerIn Proceedings of the Genetic and Evolutionary Computation Conference, 2024
Reinforcing Inter-Class Dependencies in the Asymmetric Island ModelAndrew Festa, Gaurav Dixit, and Kagan TumerIn Proceedings of the Genetic and Evolutionary Computation Conference, 2024Best Paper Award Finalist in the Evolutionary Machine Learning track
Multiagent learning allows agents to learn cooperative behaviors necessary to accomplish team objectives. However, coordination requires agents to learn diverse behaviors that work well as part of a team, a task made more difficult by all agents simultaneously learning their own individual behaviors. This is made more challenging when there are multiple classes of asymmetric agents in the system with differing capabilities that work together as a team. The Asymmetric Island Model alleviates these difficulties by simultaneously optimizing for class-specific and team-wide behaviors as independent processes that enable agents to discover and refine optimal joint-behaviors. However, agents learn to optimize agent-specific behaviors in isolation from other agent classes, leading them to learn egocentric behaviors that are potentially sub-optimal when paired with other agent classes. This work introduces Reinforced Asymmetric Island Model (RAIM), a framework for explicitly reinforcing closely dependent inter-class agent behaviors. When optimizing the class-specific behaviors, agents learn alongside stationary representations of other classes, allowing them to efficiently optimize class-specific behaviors that are conditioned on the expectation of the behaviors of the complementary agent classes. Experiments in an asymmetric harvest environment highlight the effectiveness of our method in learning robust inter-agent behaviors that can adapt to diverse environment dynamics.
 Objective-Informed Diversity for Multi-Objective Multiagent Coordination.Gaurav Dixit and Kagan TumerIn ECAI, 2024
Objective-Informed Diversity for Multi-Objective Multiagent Coordination.Gaurav Dixit and Kagan TumerIn ECAI, 2024To coordinate in multiagent settings characterized by multiple objectives, asymmetric agents (agents with distinct capabilities and preferences) must learn diverse behaviors to balance trade-offs between agent-specific and team objectives. Hierarchical methods partially address this by leveraging a combination of Quality-Diversity methods that illuminate the behavior space and evolutionary algorithms that use non-dominated sorting over the explored behaviors to improve coverage in the objective space. However, optimizing diverse behaviors and trade-offs in isolation is susceptible to producing egocentric behaviors that favor agent-specific objectives at the cost of team objectives. This work introduces the Multi-Objective Informed Island Model (MOI-IM), an asymmetric multiagent learning framework that fosters diverse behaviors and rich inter-agent relationships, necessary to balance potentially conflicting and misaligned objectives. An evolutionary algorithm improves coverage in the objective space by evolving a population of teams, while a gradient-based optimization infers and progressively explores the behavior space by fluidly adapting search to regions that produce policies with non-dominated trade-offs. The two processes are coupled via shared replay buffers to ensure alignment between coverage in the behavior and objective space. Empirical results on an asymmetric multi-objective coordination problem highlight MOI-IM’s ability to produce teams that can express diverse trade-offs and robust relationships required to balance misaligned objectives.
2023
 Learning Inter-Agent Synergies in Asymmetric Multiagent SystemsGaurav Dixit and Kagan TumerIn AAMAS, 2023
Learning Inter-Agent Synergies in Asymmetric Multiagent SystemsGaurav Dixit and Kagan TumerIn AAMAS, 2023In multiagent systems that require coordination, agents must learn diverse policies that enable them to achieve their individual and team objectives. Multiagent Quality-Diversity methods partially address this problem by filtering the joint space of policies to smaller sub-spaces that make the diversification of agent policies tractable. However, in teams of asymmetric agents (agents with different objectives and capabilities), the search for diversity is primarily driven by the need to find policies that will allow agents to assume complementary roles required to work together in teams. This work introduces Asymmetric Island Model (AIM), a multiagent framework that enables populations of asymmetric agents to learn diverse complementary policies that foster teamwork via dynamic population size allocation on a wide variety of team tasks. The key insight of AIM is that the competitive pressure arising from the distribution of policies on different team-wide tasks drives the agents to explore regions of the policy space that yield specializations that generalize across tasks. Simulation results on multiple variations of a remote habitat problem highlight the strength of AIM in discovering robust synergies that allow agents to operate near-optimally in response to the changing team composition and policies of other agents.
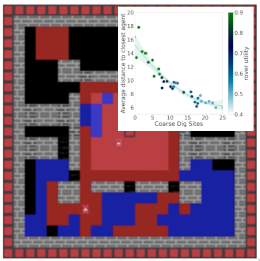 Learning synergies for multi-objective optimization in asymmetric multiagent systemsGaurav Dixit and Kagan TumerIn Proceedings of the Genetic and Evolutionary Computation Conference, 2023
Learning synergies for multi-objective optimization in asymmetric multiagent systemsGaurav Dixit and Kagan TumerIn Proceedings of the Genetic and Evolutionary Computation Conference, 2023Agents in a multiagent system must learn diverse policies that allow them to express complex inter-agent relationships required to optimize a single team objective. Multiagent Quality Diversity methods partially address this by transforming the agents’ large joint policy space to a tractable sub-space that can produce synergistic agent policies. However, a majority of real-world problems are inherently multi-objective and require asymmetric agents (agents with different capabilities and objectives) to learn policies that represent diverse trade-offs between agent-specific and team objectives. This work introduces Multi-objective Asymmetric Island Model (MO-AIM), a multi-objective multiagent learning framework for the discovery of generalizable agent synergies and trade-offs that is based on adapting the population dynamics over a spectrum of tasks. The key insight is that the competitive pressure arising from the changing populations on the team tasks forces agents to acquire robust synergies required to balance their individual and team objectives in response to the nature of their teams and task dynamics. Results on several variations of a multi-objective habitat problem highlight the potential of MO-AIM in producing teams with diverse specializations and trade-offs that readily adapt to unseen tasks.
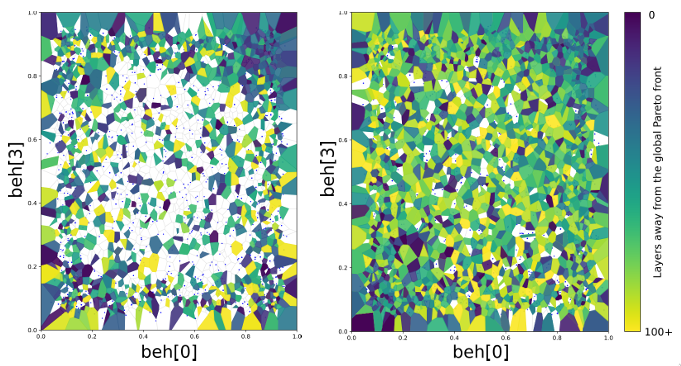 Shaping the Behavior Space with Counterfactual Agents in Multi-Objective Map Elites.Anna Nickelson, Nicholas Zerbel, Gaurav Dixit, and 1 more authorIn IJCCI, 2023
Shaping the Behavior Space with Counterfactual Agents in Multi-Objective Map Elites.Anna Nickelson, Nicholas Zerbel, Gaurav Dixit, and 1 more authorIn IJCCI, 2023Success in many real-world problems cannot be adequately defined under a single objective and instead requires multiple, sometimes competing, objectives to define the problem. To perform well in these environ-ments, autonomous agents need to have a variety of skills and behaviors to balance these objectives. The combination of Multi-Objective Optimization (MOO) and Quality Diversity (QD) methods, such as in MultiObjective Map Elites (MOME), aim to provide a set of policies with diverse behaviors that cover multiple objectives. However, MOME is unable to diversify its search across the behavior space, resulting in significantly reduced coverage of the global Pareto front. This paper introduces Counterfactual Behavior Shaping for Multi-Objective Map Elites (C-MOME), a method that superimposes counterfactual agents onto the state space of a learning agent to more richly define the diversity of agent behaviors. Counterfactuals explicitly introduce new forms of diversity in agent behavior
2022
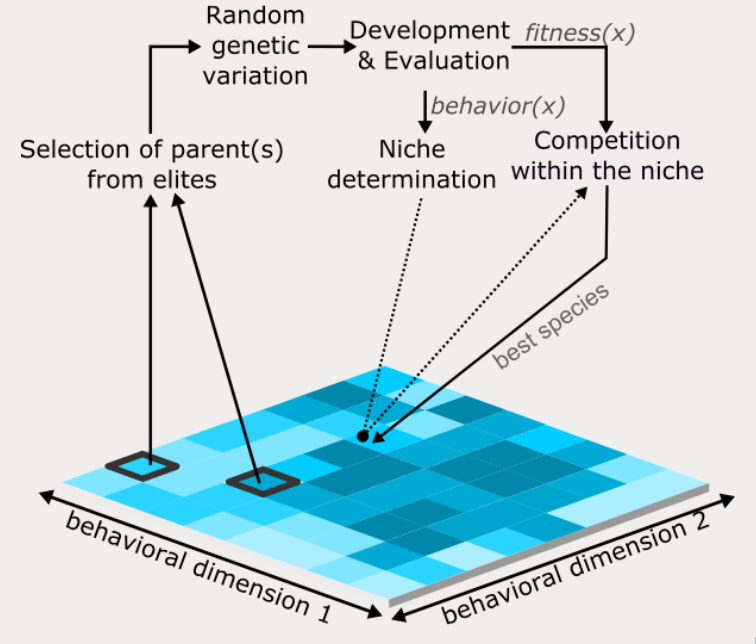 Balancing teams with quality-diversity for heterogeneous multiagent coordinationGaurav Dixit and Kagan TumerIn Proceedings of the Genetic and Evolutionary Computation Conference Companion, 2022
Balancing teams with quality-diversity for heterogeneous multiagent coordinationGaurav Dixit and Kagan TumerIn Proceedings of the Genetic and Evolutionary Computation Conference Companion, 2022Evolutionary optimization is difficult in domains that require heterogeneous agents to coordinate on diverse tasks as agents often converge to a limited set of "acceptable" behaviors. Quality-Diversity methods alleviate this problem by shifting the focus from optimizing to finding a diverse repertoire of behaviors. However, in multiagent environments with diverse and tightly-coupled tasks, exploring the entire space of behaviors is often intractable. Agents must focus on searching regions of the behavior space that yield behaviors for good team performance. We extend Behavior Exploration for Heterogeneous Teams (BEHT)[4], a multi-level training framework that allows systematic exploration of the agents’ behavior space required to complete diverse tasks as a coordinated team in a dynamic environment. We show that BEHT allows agents to learn diverse synergies that are demonstrated by the diversity of acquired agent behavior in response to the changing environment and agent behaviors.
 Behavior Exploration and Team Balancing for Heterogeneous Multiagent CoordinationGaurav Dixit and Kagan TumerIn International Conference on Autonomous Agents and MultiAgent Systems, 2022
Behavior Exploration and Team Balancing for Heterogeneous Multiagent CoordinationGaurav Dixit and Kagan TumerIn International Conference on Autonomous Agents and MultiAgent Systems, 2022Diversity in behaviors is instrumental for robust team performance in many multiagent tasks which require agents to coordinate. Unfortunately, exhaustive search through the agents’ behavior spaces is often intractable. This paper introduces Behavior Exploration for Heterogeneous Teams (BEHT), a multi-level learning framework that enables agents to progressively explore regions of the behavior space that promote team coordination on diverse goals. By combining diversity search to maximize agent-specific rewards and evolutionary optimization to maximize the team-based fitness, our method effectively filters regions of the behavior space that are conducive to agent coordination. We demonstrate the diverse behaviors and synergies that are method allows agents to learn on a multiagent exploration problem.
 Diversifying behaviors for learning in asymmetric multiagent systemsGaurav Dixit, Everardo Gonzalez, and Kagan TumerIn Proceedings of the Genetic and Evolutionary Computation Conference, 2022
Diversifying behaviors for learning in asymmetric multiagent systemsGaurav Dixit, Everardo Gonzalez, and Kagan TumerIn Proceedings of the Genetic and Evolutionary Computation Conference, 2022Best Paper Award Finalist in the Evolutionary Machine Learning track
To achieve coordination in multiagent systems such as air traffic control or search and rescue, agents must not only evolve their policies, but also adapt to the behaviors of other agents. However, extending coevolutionary algorithms to complex domains is difficult because agents evolve in the dynamic environment created by the changing policies of other agents. This problem is exacerbated when the teams consist of diverse asymmetric agents (agents with different capabilities and objectives), making it difficult for agents to evolve complementary policies. Quality-Diversity methods solve part of the problem by allowing agents to discover not just optimal, but diverse behaviors, but are computationally intractable in multiagent settings. This paper introduces a multiagent learning framework to allow asymmetric agents to specialize and explore diverse behaviors needed for coordination in a shared environment. The key insight of this work is that a hierarchical decomposition of diversity search, fitness optimization, and team composition modeling allows the fitness on the team-wide objective to direct the diversity search in a dynamic environment. Experimental results in multiagent environments with temporal and spatial coupling requirements demonstrate the diversity of acquired agent synergies in response to a changing environment and team compositions.
2021
 Contrastive Identification of Covariate Shift in Image DataMatthew L Olson, Thuy-Vy Nguyen, Gaurav Dixit, and 3 more authorsIn IEEE Visualization Conference (VIS), 2021
Contrastive Identification of Covariate Shift in Image DataMatthew L Olson, Thuy-Vy Nguyen, Gaurav Dixit, and 3 more authorsIn IEEE Visualization Conference (VIS), 2021Identifying covariate shift is crucial for making machine learning systems robust in the real world and for detecting training data biases that are not reflected in test data. However, detecting covariate shift is challenging, especially when the data consists of high-dimensional images, and when multiple types of localized covariate shift affect different subspaces of the data. Although automated techniques can be used to detect the existence of covariate shift, our goal is to help human users characterize the extent of covariate shift in large image datasets with interfaces that seamlessly integrate information obtained from the detection algorithms. In this paper, we design and evaluate a new visual interface that facilitates the comparison of the local distributions of training and test data. We conduct a quantitative user study on multi-attribute facial data to compare two different learned low-dimensional latent representations (pretrained ImageNet CNN vs. density ratio) and two user analytic workflows (nearest-neighbor vs. cluster-to-cluster). Our results indicate that the latent representation of our density ratio model, combined with a nearest-neighbor comparison, is the most effective at helping humans identify covariate shift.
2020
 Gaussian processes as multiagent reward modelsGaurav Dixit, Stephane Airiau, and Kagan TumerIn AAMAS Conference proceedings, 2020
Gaussian processes as multiagent reward modelsGaurav Dixit, Stephane Airiau, and Kagan TumerIn AAMAS Conference proceedings, 2020In multiagent problems that require complex joint actions, reward shaping methods yield good behavior by incentivizing the agents’ potentially valuable actions. However, reward shaping often requires access to the functional form of the reward function and the global state of the system. In this work, we introduce the Exploratory Gaussian Reward (EGR), a new reward model that creates optimistic stepping stone rewards linking the agents potentially good actions to the desired joint action. EGR models the system reward as a Gaussian Process to leverage the inherent uncertainty in reward estimates that push agents to explore unobserved state space. In the tightly coupled rover coordination problem, we show that EGR significantly outperforms a neural network approximation baseline and is comparable to the system with access to the functional form of the global reward. Finally, we demonstrate how EGR improves performance over other reward shaping methods by forcing agents to explore and escape local optima.
2019
- Dirichlet-Multinomial Counterfactual Rewards for Heterogeneous Multiagent SystemsGaurav Dixit, Nicholas Zerbel, and Kagan TumerIn IEEE Symposium on multi-robot and multi-agent systems, 2019
Multi-robot teams have been shown to be effective in accomplishing complex tasks which require tight coordination among team members. In homogeneous systems, recent work has demonstrated that “stepping stone” rewards are an effective way to provide agents with feedback on potentially valuable actions even when the agent-to-agent coupling requirements of an objective are not satisfied. In this work, we propose a new mechanism for inferring hypothetical partners in tightly-coupled, heterogeneous systems called Dirichlet-Multinomial Counterfactual Selection (DMCS). Using DMCS, we show that agents can learn to infer appropriate counterfactual partners to receive more informative stepping stone rewards by testing in a modified multi-rover exploration problem. We also show that DMCS outperforms a random partner selection baseline by over 40%, and we demonstrate how domain knowledge can be used to induce a prior to guide the agent learning process. Finally, we show that DMCS maintains superior performance for up to 15 distinct rover types compared to the performance of the baseline which degrades rapidly.